Rの乱雑なカテゴリデータを構成して再構築するにはどうすればよいですか?
 https://stackoverflow.com/questions/2769688
https://stackoverflow.com/questions/2769688
-
03-10-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russian質問
私は乱雑であり、 データセット 掃除する必要があります。
コーディングスキーム
大学の科学コース試験のデータを分析しています。私たちは学生の回答のパターンを検討しており、学生が答えてやっていることの種類を表すコーディングスキームを開発しました。コーディングスキームのサブセットを以下に示します。
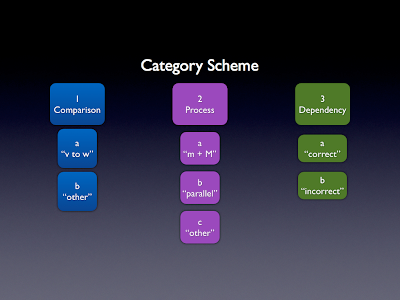
各主要なコード(1、2、3)内には、ネストされた非ユニークサブコード(a、b、...)があることに注意してください。
生データがどのように見えるか
私はあなたが見ることができる私の実際のデータの匿名化された生のサブセットを作成しました ここ。私の問題の一部は、データをコーディングした人は、一部の学生が複数のパターンを表示していることに気付いたことです。コーダーの解決策は、十分な列を作成することでした(reason1, reason2、...)複数のパターンで生徒を保持する。順序(reason1, reason2)arbitrary-2学生(学生41や学生42などデータセット)「依存関係」を正しく適用した人は、両方とも分析に登録する必要があります。 3a に表示されます reason 列または reason2 桁。
学生データを最適に構成するにはどうすればよいですか?
私の問題の一部は、です 生データ, 、すべての学生が同じ順序で同じパターン、または同じ数を表示するわけではありません。一部の生徒は1つだけをするかもしれませんが、他の生徒はいくつかをするかもしれません。したがって、模範となった学生の抽象化された表現は次のようになるかもしれません。

上記の例に注意してください student002 と student003 どちらも「1b」としてコード化されていますが、の順序を故意に違うものとして示していることを示しています。 私のデータ.
私の(実用的な)質問
- 連結する必要があります
reason1,reason2,...1つの列に? - どうすればコードできますか
reason一部の学生の多重性を反映するためにr?
ありがとう
この質問は、Rの特定の機能に関するものと同様に、優れたデータの概念化に関するものであることがわかりましたが、ここで尋ねることは適切だと思いました。質問をするのが不適切だと感じた場合は、コメントでお知らせください。StackoverFlowは、Sadface Emoticonsで受信トレイを自動的にあふれさせます。私が十分に具体的でない場合は、私に知らせてください、そして私はより明確になるために最善を尽くします。
解決
それを「長」にする:
library(reshape)
dnow <- read.csv("~/Downloads/catsample20100504.csv")
dnow <- melt(dnow, id.vars=c("Student", "instructor"))
dnow$variable <- NULL ## since ordering does not matter
subset(dnow, Student%in%c(41,42)) ## see the results
次に何をすべきかは、やりたい分析の種類に依存します。しかし、長い形式は、あなたのような不規則なデータに役立ちます。
他のヒント
PLYRからDDPLYを使用し、さまざまな理由を考慮に入れたい場合は、すべての列で分割する必要があります。ただし、最初に質問マークと余分なものをクリーンアップする必要があります。
x <- ddply(data, c("split_column1", "split_column3" etc),
summarize(result_df, stats you want from result_df))
あなたが答えようとしている(全体像)質問は何ですか?なぜこの情報はあなたにとって興味深いのですか?
「学生がこれを行う場合、彼らもこれを行う可能性が高い」などのパターンを見つけようとしていますか?
それが事実である場合、私が考慮する何か - 分析のためにデータセットをより小さなランダムサンプルに分割して、誤検知のリスクを減らします。
でも興味深い問題!
