Vous souhaitez enregistrer une arborescence binaire sur le disque pour & # 8220; 20 questions & # 8221; Jeu
 https://stackoverflow.com/questions/337868
https://stackoverflow.com/questions/337868
-
19-08-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianQuestion
En bref, j'aimerais apprendre / développer une méthode élégante pour enregistrer un arbre binaire sur un disque (un arbre général, pas nécessairement un BST). Voici la description de mon problème:
J'implémente un jeu de "20 questions". J'ai écrit un arbre binaire dont les nœuds internes sont des questions et les feuilles des réponses. L'enfant de gauche d'un nœud est le chemin que vous suivriez si quelqu'un répondait "oui". à votre question actuelle, alors que le bon enfant est un "non" réponse. Notez qu'il ne s'agit pas d'une arborescence search binaire, mais simplement d'une arborescence binaire dont le fils gauche est "Oui". et le droit est "non".
Le programme ajoute un nœud à une arborescence s'il rencontre une feuille nulle en demandant à l'utilisateur de distinguer sa réponse de celle à laquelle l'ordinateur pensait.
C’est bien, car l’arbre se construit au fur et à mesure que l’utilisateur joue. Ce qui n’est pas intéressant, c’est que je n’ai pas un bon moyen de sauvegarder l’arbre sur un disque.
J'ai envisagé de sauvegarder l'arbre en tant que représentation sous forme de tableau (pour le noeud i, l'enfant gauche est 2i + 1, et 2i + 2 droite, (i-1) / 2 pour le parent), mais ce n'est pas propre et je se retrouver avec beaucoup d’espace perdu.
Des idées pour une solution élégante pour enregistrer un arbre binaire clairsemé sur disque?
La solution
Vous pouvez le stocker récursivement:
void encodeState(OutputStream out,Node n) {
if(n==null) {
out.write("[null]");
} else {
out.write("{");
out.write(n.nodeDetails());
encodeState(out, n.yesNode());
encodeState(out, n.noNode());
out.write("}");
}
}
Concevez votre propre format de sortie moins texturé. Je suis sûr que je n'ai pas besoin de décrire la méthode pour lire le résultat.
Ceci est la traversée en profondeur d'abord. La largeur d'abord fonctionne aussi.
Autres conseils
Je ferais une traversée en ordre de niveau. C’est-à-dire que vous utilisez essentiellement un algorithme de recherche par la largeur en premier.
Vous avez:
- Créez une file d'attente dans laquelle l'élément racine est inséré
- Supprimez un élément de la file d'attente, appelez-le E
- Ajoutez les enfants gauche et droit de E dans la file d'attente. S'il n'y a pas de gauche ou de droite, il suffit de mettre une représentation de noeud nul.
- écrit le noeud E sur le disque.
- Répétez à partir de l'étape 2.
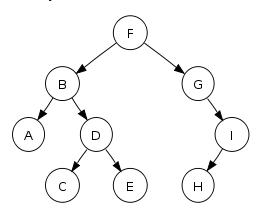
Séquence de parcours d'ordre de niveau: F, B, G, A, D, I, C, E, H
Ce que vous allez stocker sur le disque: F, B, G, A, D, NullNode, I, NullNode, NullNode, C, E, H, NullNode
Le charger à partir du disque est encore plus facile. Il suffit de lire de gauche à droite les nœuds que vous avez stockés sur le disque. Cela vous donnera les nœuds gauche et droit de chaque niveau. C'est à dire. l'arbre se remplira de haut en bas de gauche à droite.
Étape 1 lecture:
F
Étape 2 lecture:
F
B
Étape 3 lecture:
F
B G
Étape 4 lecture:
F
B G
A
Et ainsi de suite ...
Remarque: une fois que vous avez une représentation de nœud NULL, vous n’avez plus besoin de répertorier ses enfants sur le disque. Lors du chargement, vous saurez passer au nœud suivant. Donc, pour les arbres très profonds, cette solution restera efficace.
Une façon simple d’y parvenir est de parcourir l’arbre en sortie de chaque élément. Ensuite, pour charger l’arbre, il vous suffit de parcourir la liste en insérant chaque élément dans l’arbre. Si votre arborescence ne s'équilibre pas automatiquement, vous pouvez réorganiser la liste de manière à ce que l’arborescence finale soit raisonnablement équilibrée.
Pas sûr que ce soit élégant, mais c'est simple et explicable: Attribuez un ID unique à chaque nœud, qu’il s’agisse d’une tige ou d’une feuille. Un simple entier de comptage fera l'affaire.
Lors de l'enregistrement sur le disque, parcourez l'arborescence en enregistrant chaque ID de nœud, "oui". ID de lien, " no " lien ID, et le texte de la question ou de la réponse. Pour les liens nuls, utilisez zéro comme valeur nulle. Vous pouvez soit ajouter un drapeau pour indiquer s'il s'agit d'une question ou d'une réponse, ou plus simplement, vérifier si les deux liens sont nuls. Vous devriez obtenir quelque chose comme ceci:
1,2,3,"Does it have wings?"
2,0,0,"a bird"
3,4,0,"Does it purr?"
4,0,0,"a cat"
Notez que si vous utilisez l'approche des entiers séquentiels, l'enregistrement de l'ID du nœud peut être redondant, comme illustré ci-dessous. Vous pouvez simplement les mettre en ordre par ID.
Pour restaurer à partir du disque, lisez une ligne, puis ajoutez-la à l'arborescence. Vous aurez probablement besoin d’une table ou d’un tableau pour contenir les nœuds référencés en avant, par exemple. lors du traitement du nœud 1, vous devez suivre les étapes 2 et 3 jusqu'à ce que vous puissiez renseigner ces valeurs.
La méthode la plus simple et arbitraire est simplement un format de base pouvant être utilisé pour représenter n’importe quel graphe.
<parent>,<relation>,<child>
Ie:
"Is it Red", "yes", "does it have wings"
"Is it Red", "no" , "does it swim"
Il n'y a pas beaucoup de redondance ici, et les formats principalement lisibles par l'homme, la seule duplication de données est qu'il doit y avoir une copie d'un parent pour chaque enfant direct qu'il a.
La seule chose à surveiller est de ne pas générer accidentellement de cycle;)
Sauf si c'est ce que vous voulez.
Le problème ici est de reconstruire le arbre ensuite. Si je crée le " fait il a des ailes " objet en lisant le première ligne, je dois en quelque sorte localiser quand je rencontre plus tard la ligne lire " a-t-il ailes "," oui "," a-t-il un bec? "
C’est la raison pour laquelle j’utilise traditionnellement des structures de graphes en mémoire, avec des pointeurs allant partout.
[0x1111111 "Is It Red" => [ 'yes' => 0xF752347 , 'no' => 0xFF6F664 ],
0xF752347 "does it have wings" => [ 'yes' => 0xFFFFFFF , 'no' => 0x2222222 ],
0xFF6F664 "does it swim" => [ 'yes' => "I Dont KNOW :( " , ... etc etc ]
Ensuite, le " enfant / parent " la connectivité n'est que des métadonnées.
En Java, si vous voulez rendre une classe sérialisable, vous pouvez simplement écrire l’objet de classe sur le disque et le relire à l’aide de flux d’entrée / sortie.
Je stockerais l'arbre comme ceci:
<node identifier>
node data
[<yes child identfier>
yes child]
[<no child identifier>
no child]
<end of node identifier>
où les nœuds enfants ne sont que des instances récursives de ce qui précède. Les bits entre [] sont facultatifs et les quatre identificateurs ne sont que des constantes / valeurs enum.
Voici le code C ++ qui utilise PreOrder DFS:
void SaveBinaryTreeToStream(TreeNode* root, ostringstream& oss)
{
if (!root)
{
oss << '#';
return;
}
oss << root->data;
SaveBinaryTreeToStream(root->left, oss);
SaveBinaryTreeToStream(root->right, oss);
}
TreeNode* LoadBinaryTreeFromStream(istringstream& iss)
{
if (iss.eof())
return NULL;
char c;
if ('#' == (c = iss.get()))
return NULL;
TreeNode* root = new TreeNode(c, NULL, NULL);
root->left = LoadBinaryTreeFromStream(iss);
root->right = LoadBinaryTreeFromStream(iss);
return root;
}
Dans main () , vous pouvez faire:
ostringstream oss;
root = MakeCharTree();
PrintVTree(root);
SaveBinaryTreeToStream(root, oss);
ClearTree(root);
cout << oss.str() << endl;
istringstream iss(oss.str());
cout << iss.str() << endl;
root = LoadBinaryTreeFromStream(iss);
PrintVTree(root);
ClearTree(root);
/* Output:
A
B C
D E F
G H I
ABD#G###CEH##I##F##
ABD#G###CEH##I##F##
A
B C
D E F
G H I
*/
Le DFS est plus facile à comprendre.
*********************************************************************************
Mais nous pouvons utiliser le niveau d'analyse BFS en utilisant une file d'attente
ostringstream SaveBinaryTreeToStream_BFS(TreeNode* root)
{
ostringstream oss;
if (!root)
return oss;
queue<TreeNode*> q;
q.push(root);
while (!q.empty())
{
TreeNode* tn = q.front(); q.pop();
if (tn)
{
q.push(tn->left);
q.push(tn->right);
oss << tn->data;
}
else
{
oss << '#';
}
}
return oss;
}
TreeNode* LoadBinaryTreeFromStream_BFS(istringstream& iss)
{
if (iss.eof())
return NULL;
TreeNode* root = new TreeNode(iss.get(), NULL, NULL);
queue<TreeNode*> q; q.push(root); // The parents from upper level
while (!iss.eof() && !q.empty())
{
TreeNode* tn = q.front(); q.pop();
char c = iss.get();
if ('#' == c)
tn->left = NULL;
else
q.push(tn->left = new TreeNode(c, NULL, NULL));
c = iss.get();
if ('#' == c)
tn->right = NULL;
else
q.push(tn->right = new TreeNode(c, NULL, NULL));
}
return root;
}
Dans main () , vous pouvez faire:
root = MakeCharTree();
PrintVTree(root);
ostringstream oss = SaveBinaryTreeToStream_BFS(root);
ClearTree(root);
cout << oss.str() << endl;
istringstream iss(oss.str());
cout << iss.str() << endl;
root = LoadBinaryTreeFromStream_BFS(iss);
PrintVTree(root);
ClearTree(root);
/* Output:
A
B C
D E F
G H I
ABCD#EF#GHI########
ABCD#EF#GHI########
A
B C
D E F
G H I
*/
